Introducing the New Overview AI
Overview AI in Debrev Interview now runs a tiered memory architecture with semantic search, so every candidate in your pool stays permanently in scope while deep analysis is targeted to the handful most relevant to each question. A lightweight ~13-token index keeps the full roster visible at all times, full Tier 2 detail is retrieved for a relevant few per question, and a deliberate ingestion order protects the output format and roster from ever being trimmed. In measured evaluations against a real 48-candidate pool the architecture held 100% candidate coverage on every turn (versus 6.3% on the old 4,000-token setup), vector retrieval scored 3.8× above random, and follow-up turns recompiled in ~10ms. On Pro and Enterprise, a new Agentic Candidate Lookup lets the AI fetch a missing profile mid-conversation, flipping confident wrong answers to correct ones in every verified recovery.
A smarter, faster way to understand your entire candidate pool — every candidate always in scope, every question answered with precision.
Overview AI in Debrev Interview now runs a tiered memory architecture with semantic search. Every candidate in your pool is permanently visible to the AI. Deep analysis is targeted to the handful of candidates most relevant to each question. Follow-up questions get the same quality of attention as the first, no matter how long the conversation runs.
How It Works: Two Tiers of Context
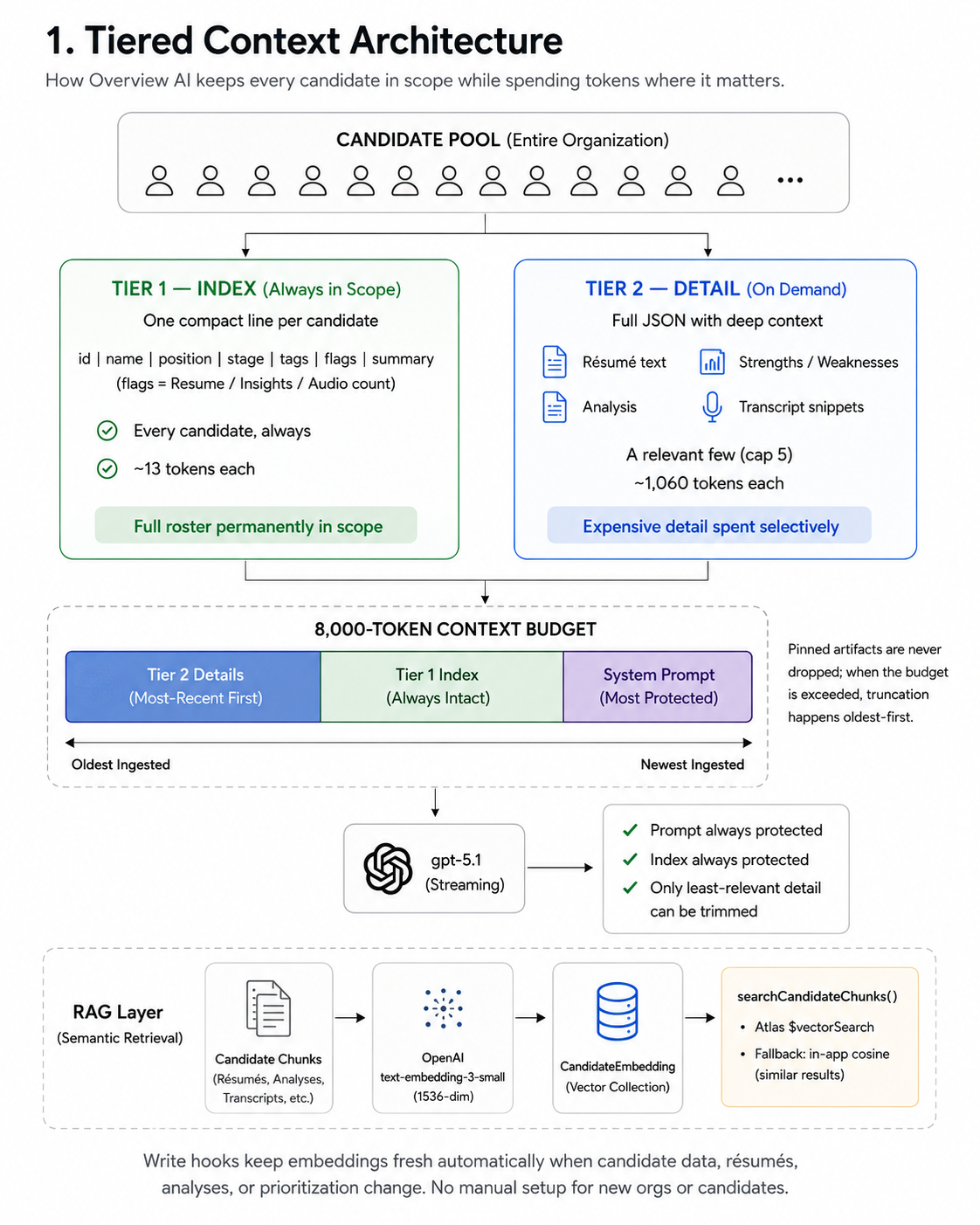
Overview AI manages your candidate pool in two tiers. The first keeps a lightweight index of every candidate permanently in context. The second holds full rich detail, but only for the candidates most relevant to what you just asked. This combination keeps the AI's view of your pipeline complete while concentrating its analytical power exactly where it is needed.
| Tier | What it stores | Size | Who |
|---|---|---|---|
| Tier 1 — Index | One compact line per candidate: id | name | position | stage | tags | flags | summary. Summary is built deterministically — no LLM call, no latency cost. |
~13 tokens each | Every candidate, always in scope |
| Tier 2 — Detail | Full JSON: resume text, strengths/weaknesses, transcript snippets, analysis | ~1,060 tokens each | A relevant few (cap of 5) chosen per question |
The index entry for each candidate is built deterministically from existing data — no additional AI call, no latency, no cost. The summary field is computed and cached on the candidate record so it is always ready.
Why Ingestion Order Is the Load-Bearing Detail
The AI runtime operates on a fixed 8,000-token budget. When the budget is full, it trims the oldest-ingested content first. Overview AI exploits this by ingesting in a deliberate order:
- Full detail for selected candidates goes in first.
- The Tier 1 index of everyone goes in second.
- The system prompt goes in last — making it the most protected item.
Result: the output format (system prompt) and the full candidate roster (index) are always intact. Only the least-relevant detail entry can ever be trimmed, and it degrades gracefully rather than disappearing at once.
Architecture Overview
A Live Request, Step by Step
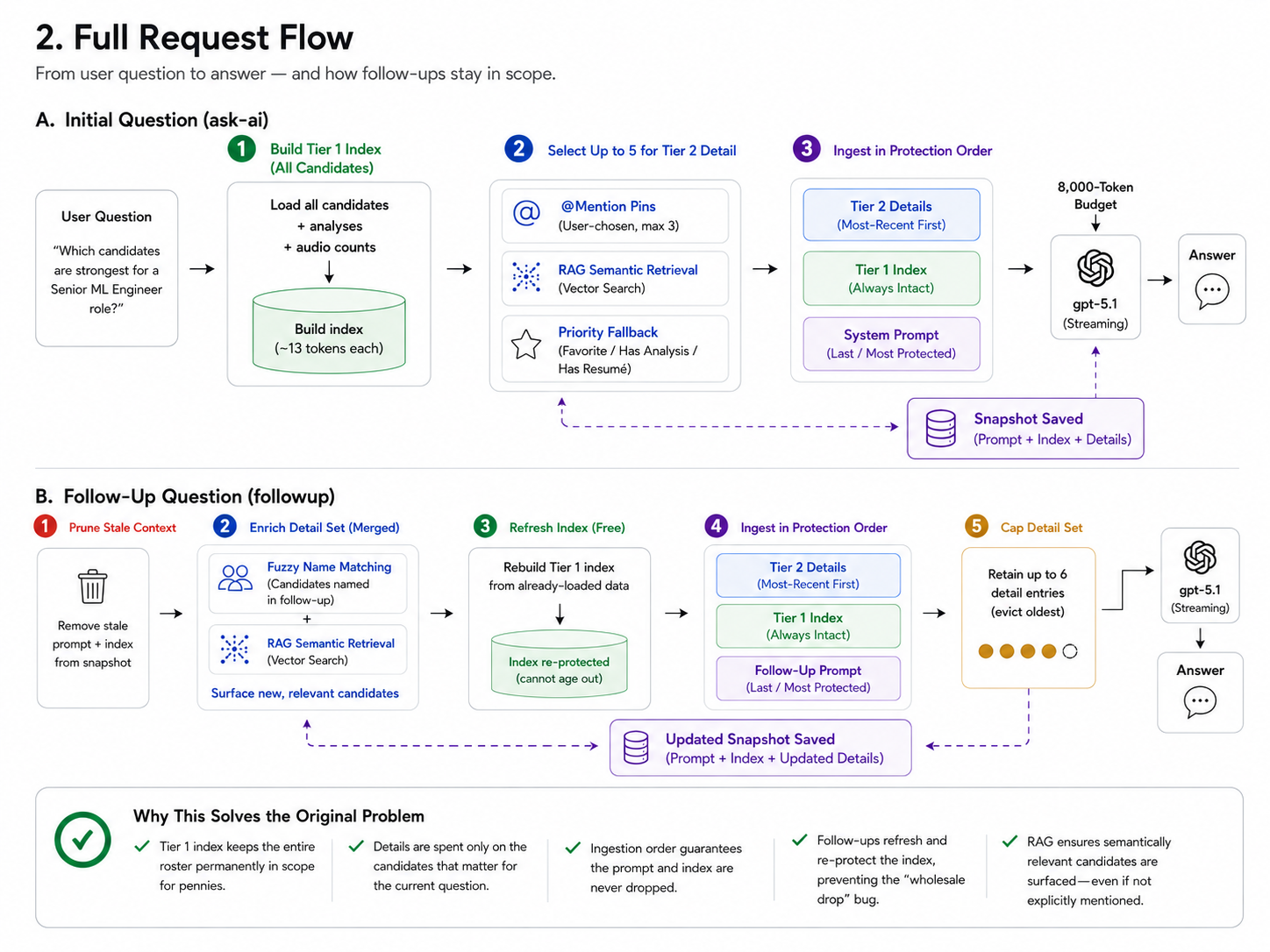
Here is what actually happens when you ask Overview AI a question. First you open the overview and ask; the system trace runs in the background.
Step 1 — You open the overview and ask a question. You open the Overview tab for a role. The AI loads your candidate pool in the background, resumes are indexed automatically on first load, and then you type: "Who are the strongest backend engineers in this pool?"
// Candidate pool loads; resume PDFs are embedded
[indexing resume PDFs]
// Tier 1 index built for all candidates (~13 tok each)
// Index is injected into context — no LLM call needed
// RAG vector search runs against question embedding
searchCandidateChunks: attempting $vectorSearch
searchCandidateChunks: $vectorSearch returned 20 results
// Top 5 candidates selected for Tier 2 detail
RAG retrieved (ask-ai): [
'6a2333e5...', // strongest semantic match
'69c0b8af...',
'69c0b8a3...',
'69c0b8a4...',
'693761e2...'
]
// Memory compiled: detail first, index second, prompt last
Memory compile: { tokenEstimate: 5966, includedArtifacts: 7, droppedArtifacts: 0 }
>>> POST /api/overview/ask-ai 200 9.3s
>>> (compile: 1,053ms | render: 8.3s)
Step 2 — You ask a follow-up question. You ask: "What candidates are similar to Broad Lance that you have not already mentioned?"
// Snapshot restored from previous turn
Followup incoming: { hasSnapshot: true, eventsCount: 16, artifactsCount: 12 }
// Stale prompt + index pruned from snapshot
// RAG runs again against the new question
searchCandidateChunks: $vectorSearch returned 20 results
// Fuzzy name match pins 'Broad Lance' as anchor
Followup RAG retrieved: [
'6a2333e5...', // already known — skipped
'69c0b8a6...', // NEW
'693761e2...', // already known — skipped
'69c0b8ae...', // NEW
'69c0b8a1...' // NEW
]
// 3 net-new candidates added to detail set
Enriched candidates: ['69c0b8a6...','69c0b8ae...','69c0b8a1...']
// Index rebuilt free, details capped at 6
Memory compile (followup): { tokenEstimate: 8000, includedArtifacts: 16, droppedArtifacts: 0 }
>>> POST /api/overview/ask-ai/followup 200 14.7s
>>> (compile: 10ms | render: 14.6s)
Compile time: 1,053ms on the first question (RAG + full context build), then just 10ms on the follow-up. The context is fully refreshed between every turn, and the cost of doing so is nearly zero.
How Follow-Ups Stay Sharp
Each follow-up runs a five-step context refresh before the AI sees anything:
- Prune the stale prompt and index from the restored snapshot.
- Enrich the detail set from two merged signals: fuzzy name-matching for any candidates you mention by name, and RAG semantic retrieval for conceptually similar candidates. A question like "who is similar to X that you have not mentioned?" genuinely surfaces new people.
- Rebuild the index for free from already-loaded data, then re-ingest it so it can never age into the trim zone.
- Ingest the follow-up prompt last, giving it maximum protection in the budget.
- Cap retained detail entries at 6, evicting the oldest, so the snapshot stays lean across a long conversation.
Request Flow: Initial Question and Follow-Ups
Measured Performance
We ran two evaluations against a real 48-candidate pool across 24 hiring questions to quantify how the tiered architecture and semantic retrieval perform in practice.
Evaluation 1: Candidate coverage by conversation phase
We replayed a 5-turn conversation against three configurations: the old architecture at its original 4,000-token budget, the same old architecture with the budget doubled to 8,000, and the new tiered architecture at 8,000 tokens. We measured what fraction of the 48-candidate roster was preserved in the compiled context at each phase.
At the original 4,000-token budget, only 3 of 48 candidate records survived the first question — a 6.3% coverage rate. Doubling the budget to 8,000 improved the first turn to 29%, but still left more than two-thirds of the pool unreachable. The tiered architecture holds at 100% from the very first question onward, with no degradation across follow-up turns.
One honest caveat: the old@8000 follow-up figure (~83%) is flattered. Those surviving entries contained no resume text or transcripts — the old follow-up route omitted them entirely. Effective coverage in terms of useful context was significantly lower than the number suggests.
Evaluation 2: RAG precision@5 by retrieval method
For 24 hiring questions, we scored three retrieval methods against an oracle: gpt-5.1 given every candidate's full data with no token budget, establishing a ground-truth relevant set. Each method's top-5 retrieved candidates were scored against that oracle. This eliminates a confounding factor in simpler metrics — the model will discuss whatever has full detail in context, so a naive "referenced in answer" score saturates at 64–87% for every method including random.
Keyword retrieval leads overall on this dataset at 50.8%, with vector search at 40%. The reason is specific to the current state of the data: only 7 of 48 candidates have full AI analyses, so most vector embeddings are built from thin resume chunks where literal term matching is competitive. Vector search leads on semantic role-fit questions where the query and resume surface different vocabulary for the same concept.
The signal that matters: vector retrieval scores 3× above random, confirming the embeddings are doing real work. Both methods beat random by a large margin, and the per-question breakdown points directly to the roadmap: hybrid retrieval combining vector and keyword results would likely outperform either approach alone.
The Semantic Search Layer
Every candidate has an embedding stored in a companion collection, generated with OpenAI text-embedding-3-small at 1536 dimensions. When Overview AI selects which candidates deserve full Tier 2 detail, it runs a vector search to find the most semantically relevant matches for your specific question.
The search uses Atlas Vector Search where available and falls back to in-app cosine similarity automatically. Results are identical either way, and the fallback is transparent. Embeddings stay current without any manual action: whenever a candidate profile, resume, analysis, or interview diarization changes, the embedding updates automatically. New organisations and new candidates are ready out of the box.
Token Budget and Plan Controls
The system operates on a fixed 8,000-token budget per request. Depth is bounded by two caps: up to 5 candidates receive full Tier 2 detail on a fresh question, and up to 6 detail entries are retained across a follow-up conversation. These numbers keep costs predictable and responses fast at standard plan sizes.
Both caps live behind a single plan-gating function. Increasing depth for Pro or Enterprise plans requires a one-line change with no modifications to the core architecture.
What This Means for Your Hiring Workflow
Starting with this release:
- Every candidate in your pool is always findable. Ask about anyone by name and the AI will surface them.
- Use @mentions to pin specific candidates into focus for any question — they are guaranteed a Tier 2 detail slot.
- Similarity questions actually work. "Who else is like this person that you have not mentioned?" retrieves semantically similar candidates, not just the ones already in view.
- Long conversations stay sharp. The AI refreshes its full view of the pool on every follow-up turn at near-zero compile cost.
This is part of a broader set of improvements shipping in the next version of Debrev Interview. More details coming soon.
Agentic Candidate Lookup Pro & Enterprise
The tiered architecture ensures every candidate stays in scope. But every answer still comes from a fixed working set assembled at request time. For most teams most of the time, that set contains whoever is being asked about. As candidate pools grow past a few dozen people, a specific candidate may fall outside the top-K retrieval window.
Agentic Candidate Lookup gives Overview AI a way to go check — live, mid-conversation, without the recruiter needing to rephrase or manually open a profile. When the AI determines a question calls for detail it does not already have, it calls one of three tools:
getCandidateDetails— pulls a specific candidate's full record into context.searchCandidates— runs a targeted query across the full candidate pool.compareCandidates— retrieves two profiles side-by-side for a direct comparison.
The loop is capped at 3 rounds per response. On everyday queries where the relevant profile is already in the working context, tools are not called at all — there is no overhead for the common case.
Early testing results
We ran an evaluation across 8 candidates, each tested with a buried-fact question — a specific skill present in their full resume but absent from the one-line index summary. We tested two scenarios: natural (real retrieval behavior, candidate may or may not land in the working set) and ablated (target candidate's full record explicitly excluded, simulating a growing pipeline where not every profile fits the detail window).
When the relevant candidate was already in the working context — the common case — agentic and tiered were identical: 8 of 8 correct in both conditions. Adding tools does not change accuracy on ordinary queries.
In the out-of-context scenario, tiered answered correctly on 1 of 8. Agentic answered correctly on 5 of 8 — and in every case where it chose to call getCandidateDetails, the answer flipped from wrong to correct.
The 3 verified recoveries
In every case where the agentic condition fetched the missing record, the answer converted from a confident wrong answer to a correct one, citing the specific skill from the candidate's resume:
| Candidate | Fact asked about | Phase 1+2 | Phase 3 |
|---|---|---|---|
| Grady D | React Native | ✗ Confident: no relevant experience | ✓ Fetched full profile (1 call) — confirmed React Native app built at Redacted Interactive |
| J** B*** | Apache Spark | ✗ Confident: no relevant experience | ✓ Fetched full profile (1 call) — confirmed Apache Spark pipelines at Oracle |
| M**** C***** | Ruby on Rails | ✗ Confident: no relevant experience | ✓ Fetched full profile (1 call) — confirmed Ruby on Rails in resume skills list |
Every time the assistant looked up a missing profile, it answered correctly. The lookup mechanism works reliably. The remaining headroom is in the heuristics for when to trigger a fetch — not every out-of-window query prompted a tool call in this test.
Reading the numbers honestly
The defensible, mechanically-attributed result is 3 of 3 fetch-driven recoveries. Two of the 5 agentic correct answers in the out-of-context scenario involved zero tool calls, which looks like response stochasticity rather than a Phase 3 effect. We do not attribute those to the tool-use mechanism.
The out-of-context scenario is a forward-looking scale test, not a description of what most teams experience today. At 48 candidates, the natural retrieval window already covers the asked-about profile most of the time. The scenario becomes more relevant as pipelines grow.
Latency: agentic responses take ~1.2s longer on average than tiered in the same scenario (4,035ms vs 2,847ms in-context; 4,666ms vs 4,259ms out-of-context). The overhead is real and modest, attributable primarily to the larger request payload from the tools schema.
Agentic Candidate Lookup is available on Pro and Enterprise plans. The tiered context architecture, semantic search, and follow-up refresh apply to all plans.
Ready to transform your hiring process?
Discover how Debrev Interview can help your team make better hiring decisions.
Explore Debrev Interview